

Genesis分析
Taichi
@ti.func & @ti.kernel
When writing compute-intensive tasks, users can leverage Taichi's high performance computation by following a set of extra rules, and making use of the two decorators
@ti.funcand@ti.kernel. These decorators instruct Taichi to take over the computation tasks and compile the decorated functions to machine code using its just-in-time (JIT) compiler. As a result, calls to these functions are executed on multi-core CPUs or GPUs and can achieve acceleration by 50x~100x compared to native Python code.在编写计算密集型任务时,用户可以通过遵循一组额外规则并使用两个装饰器
@ti.func和@ti.kernel来利用 Taichi 的高性能计算。这些装饰器指示 Taichi 接管计算任务,并使用其即时 (JIT) 编译器将装饰函数编译为机器代码。因此,对这些函数的调用在多核 CPU 或 GPU 上执行,与原生 Python 代码相比,可以实现 50 倍~100 倍的加速。
@ti.kernel: 用 @ti.kernel 修饰的函数称为 Taichi 内核或简称为内核。这些函数是Taichi运行时接管任务的入口点,它们必须由Python代码直接调用。您可以使用原生 Python 来准备任务,例如从磁盘读取数据和预处理,然后调用内核将计算密集型任务卸载到 Taichi。
@ti.func: 用 @ti.func 修饰的函数称为 Taichi 函数。这些函数是内核的构建块,只能由另一个 Taichi 函数或内核调用。与普通的 Python 函数一样,您可以将任务划分为多个 Taichi 函数,以增强可读性并在不同的内核中重用它们。
Notes:
- Taichi 要求内核的参数和返回值进行类型提示,除非它既没有参数也没有返回语句。
- 内核或 Taichi 函数内的代码是 Taichi 范围的一部分。 Taichi 的运行时在多核 CPU 或 GPU 设备上并行编译和执行该代码,以实现高性能计算。 Taichi 作用域相当于 CUDA 的设备端。
- Taichi 范围之外的代码属于 Python 范围。这段代码是用原生Python编写的,并由Python的虚拟机执行,而不是由Taichi的运行时执行。 Python 作用域相当于 CUDA 的主机端。
Kernel Notes
- 一个内核可以接受多个参数。但是,请务必注意,您不能将任意 Python 对象传递给内核。这是因为 Python 对象可以是动态的,并且可能包含 Taichi 编译器无法识别的数据。
- 标量、
ti.types.matrix()、ti.types.vector()和ti.types.struct()按值传递,这意味着内核收到参数的副本。但是,ti.types.ndarray()和ti.template()是通过引用传递的,这意味着对内核内部参数所做的任何更改也会影响原始值。 - 您可以使用
ti.types.ndarray()作为类型提示,将ndarray从 NumPy 或tensor从 PyTorch 传递到内核。 Taichi 可以识别这些数据结构的形状和数据类型,这使您可以在内核中访问它们的属性。 - 最多允许有一个返回值,该返回值可以是标量、
ti.types.matrix()或ti.types.vector()。此外,在基于 LLVM 的后端(CPU 和 CUDA 后端)中,返回值也可以是ti.types.struct()。 - 全局变量视为编译时常量。这意味着它在编译时获取全局变量的当前值,并且之后不会跟踪它们的更改。
Func Notes:
- 所有的 Taichi 函数都被强制内联 -> 不允许运行时递归。
- Taichi 函数可以接受多个参数,其中可能包括标量、
ti.types.matrix()、ti.types.vector()、ti.types.struct()、ti.types.ndarray()、ti.field()类型。 - 可以有多个返回值。
Comparison
| kernel | func | |
|---|---|---|
| 调用范围 | Python 作用域 | Taichi 作用域 |
| 参数的类型提示 | 必需 | 推荐 |
| 返回值的类型提示 | 必需 | 推荐 |
| 返回类型 | 标量ti.types.matrix()ti.types.vector()ti.types.struct()(Only on LLVM-based backends) | 标量ti.types.matrix()ti.types.vector()ti.types.struct()... |
| 参数中元素数量上限 | 32(适用于 OpenGL)64(适用于其他后端) | 无限制 |
| return 语句中返回值数量上限 | 1 | 无限 |
@ti.dataclass
1 |
|
Field
Taichi field 是全局数据容器,从 Python 作用域或 Taichi 作用域均能访问。
1 | f_2d = ti.field(int, shape=(3, 6)) # A 2D field in the shape (3, 6) |
Scalar field: 存储的是标量,是最基本的 field。
一个0D 的标量 field 是单个标量。
一个一维标量 field 是由标量组成的一个一维数组。
一个二维标量 field 是由标量组成的一个二维数组,以此类推。
1 | # Declares a 3x3 vector field comprising 2D vectors |
- Vector field: 每个元素都是
N维向量的向量场。
1 | # Declares a 300x400x500 matrix field, each of its elements being a 3x2 matrix |
Matrix field: 每个元素都是矩阵。
矩阵运算在编译时展开。
在较大的矩阵(例如
32x128)上运行可能会导致编译时间更长且性能较差。
1 | # Declares a 1D struct field using the ti.Struct.field() method |
- Struct field: 存储用户自定义的结构体。
Taichi 编译器能够自动推断底层的数据布局并应用合适的数据读取顺序。 这是 Taichi 编程语言相较其他大多数通用编程语言的一大优势。
Ndarray
ndarray总是分配一个连续的内存块,以允许与外部库进行直接的数据交换。- 与
field一样,ndarray 只能在 Python 作用域中构造,而不能在 Taichi 作用域中构造。也就是说,不能在 Taichi 内核或函数内部构造 ndarray。 - 当标量类型的 NumPy ndarray 或 PyTorch 张量作为参数传递给 Taichi 内核时,它可以被解释为标量类型数组、向量类型数组或矩阵类型数组。这是由类型提示
ti.types.ndarray()中的dtype和ndim选项控制的。
Genesis
Rigid Solver
Init
作用:初始化求解器对象,设置其初始状态和配置信息。
功能:
- 调用基类
Solver的初始化。 - 根据
options配置求解器行为:- 是否启用碰撞检测、关节限制、自碰撞。
- 最大碰撞对数量。
- 动力学积分器类型。
- 是否启用休眠优化(hibernation)。
- 初始化内部变量,如当前步数
_cur_step,以及存储实体的列表_entities。
Add Entity
作用:添加一个物理实体(如刚体、机器人、无人机等)到求解器中。
参数:
idx:实体的全局索引,用于唯一标识。material:该实体的材质类型(例如刚体或角色)。morph:实体的形态类型(例如无人机形态)。surface:几何表面信息(用于碰撞检测或渲染)。visualize_contact:是否需要可视化接触点。
功能:
- 根据
material和morph类型选择实体的类别:AvatarEntity:角色实体。DroneEntity:无人机实体。RigidEntity:普通刚体。
- 检查是否支持显示接触点(AvatarEntity不支持)。
- 初始化实体对象,并将其添加到
_entities列表中。
返回值:新创建的实体对象。
Build
作用:构建求解器的内部状态和数据结构,为模拟做好准备。
功能:
- 初始化全局变量(如环境数量
n_envs和并行级别_para_level)。 - 调用每个实体的
build方法,设置其相关参数。 - 初始化关键的数据结构:
- 自由度数量、关节数量、几何体数量等统计数据。
- 动力学矩阵(质量矩阵等)和字段(如自由度状态、几何体状态)。
- 运行初始的正向运动学(Forward Kinematics)更新几何体状态。
- 初始化碰撞检测器、约束求解器等模块。
Comparison with Genesis and Mujoco
0. Pipeline
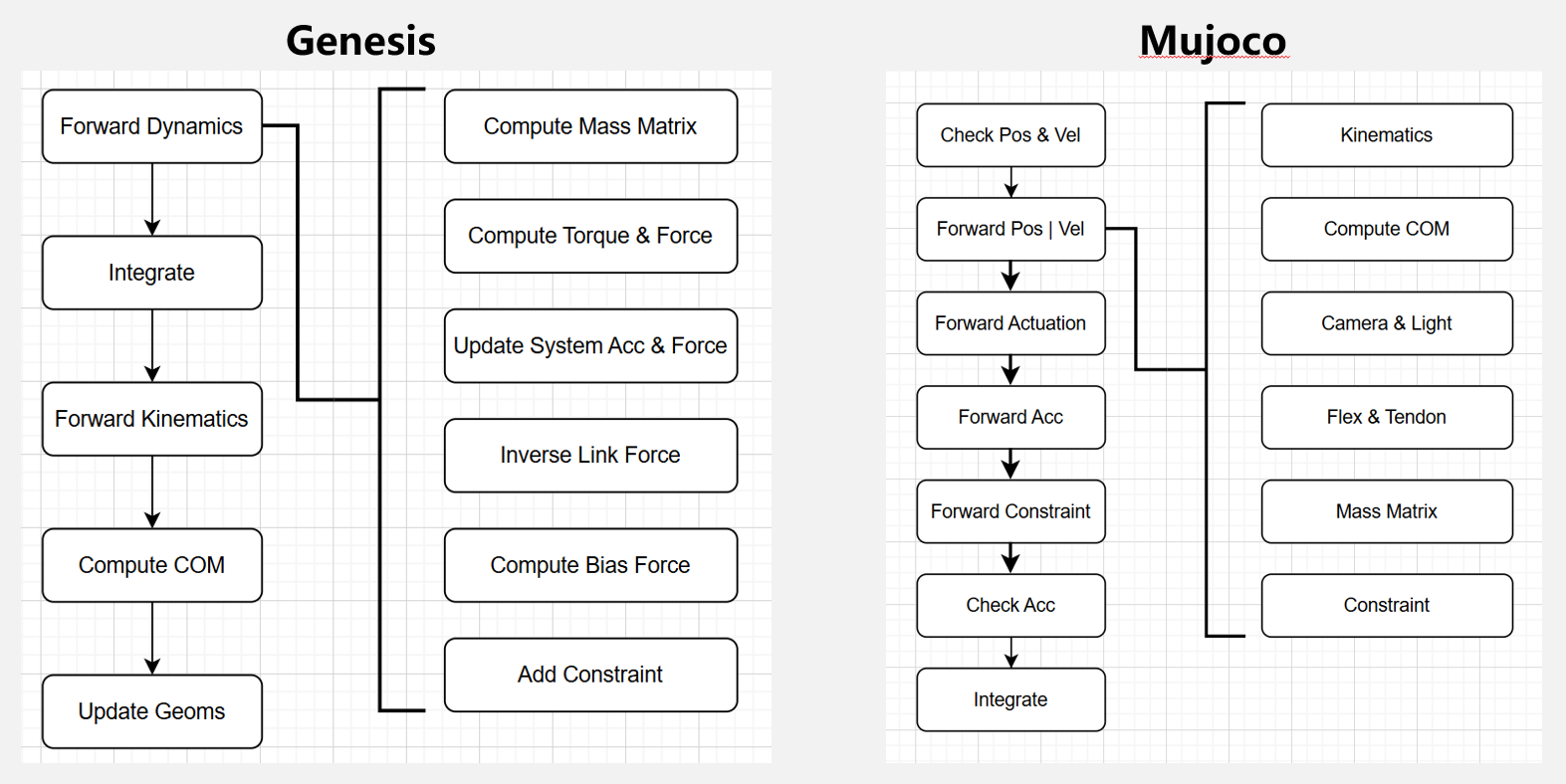
1. Mass Matrix
| Genesis | Mujoco | |
|---|---|---|
| CRB | 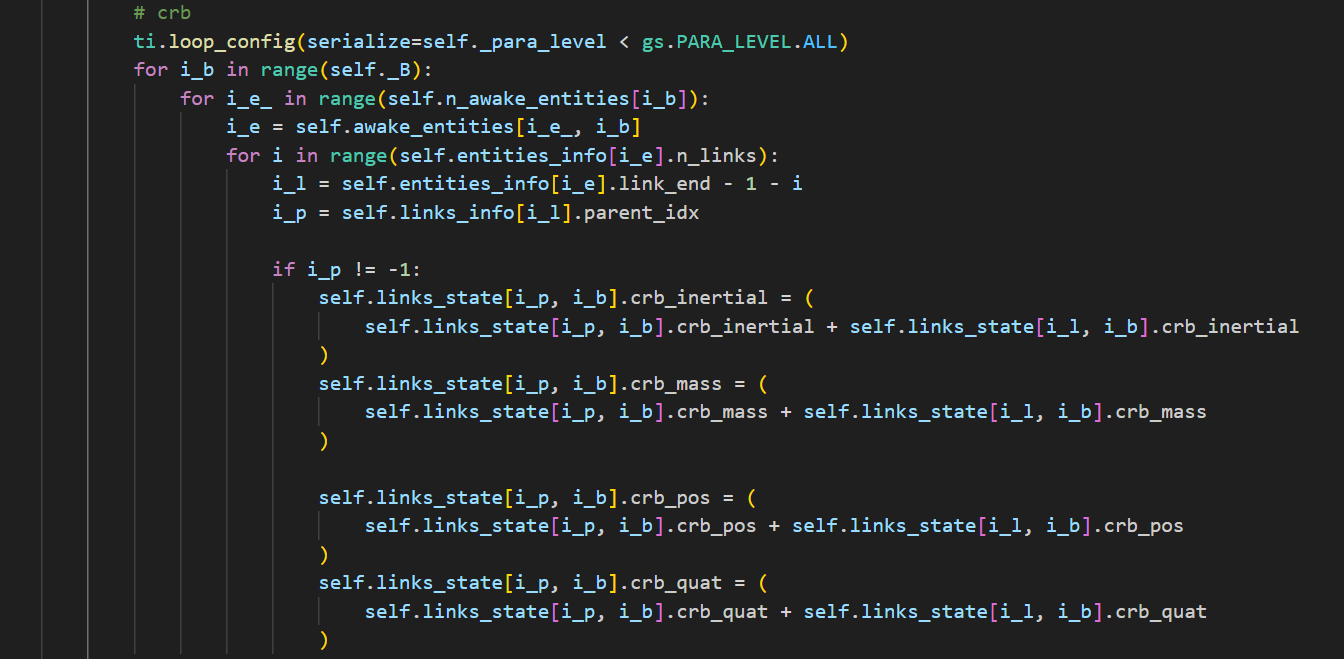 | 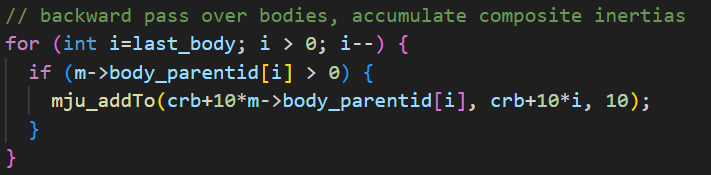 |
| Mass Matrix | 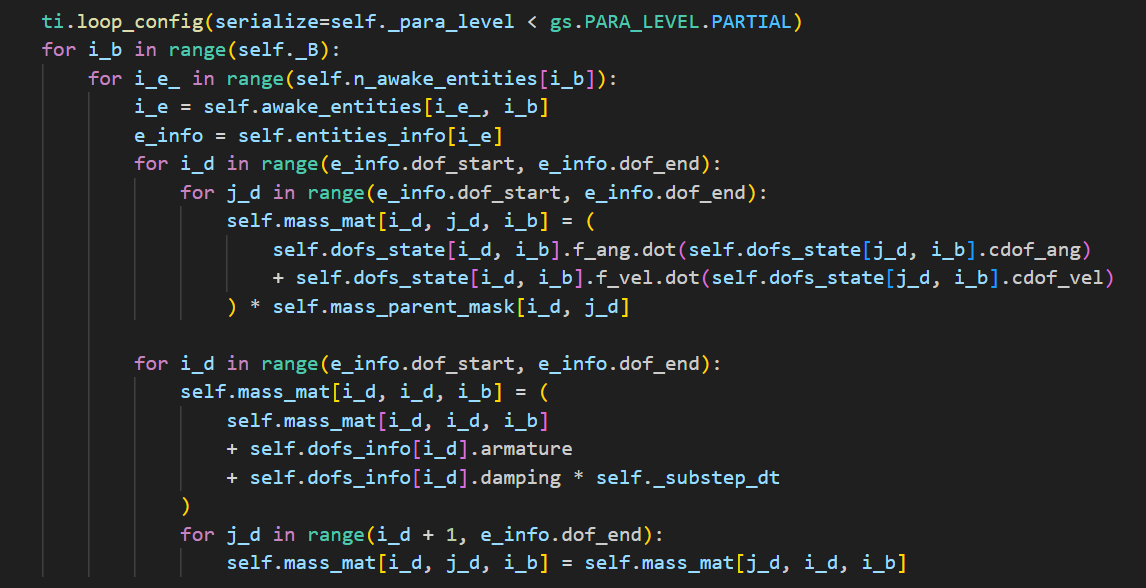 |  |
在CRB的计算中,genesis和mujoco使用了一样的策略。从末端开始遍历,自下而上地累计惯性。
有这个惯性矩阵之后,再计算每个自由度的惯性贡献,更新自由度状态 f_ang(角力矩)和 f_vel(线力矩)。然后填充这个质量矩阵。
实现细节上,genesis会有一个休眠的判断,避免了不必要的计算。此外,genesis如下定义力矩计算的函数:
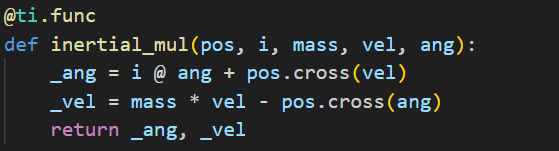
使用@ti.func修饰,将运算从Python虚拟机移到Taichi进行加速。而mujoco中此函数的处理是按照单个元素进行处理的:
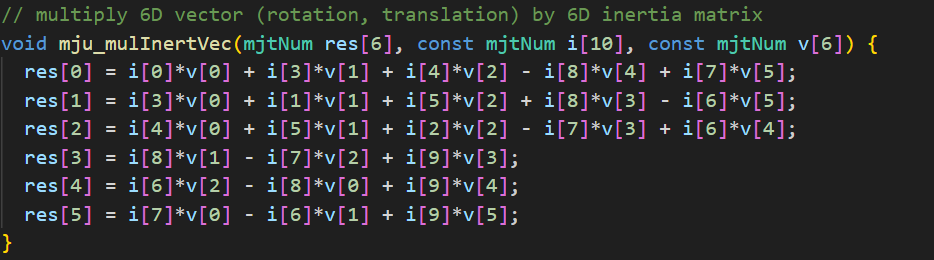
这种非连续的取值以及单元素的运算可能也是导致效率降低的原因。
2. Inversed Mass Matrix
为解释矩阵逆的计算,先简要引入两个矩阵分解方式的介绍:
| \(LU\)分解 | \(LDL^T\)分解 |
|---|---|
 |  |
genesis:
- 对质量矩阵
mass_mat进行 LU 分解。 - 使用前向和后向替代,逐列计算逆矩阵
mass_mat_inv。
在genesis中,为了简化质量矩阵的逆矩阵的计算,使用了\(LU\)分解。而在mujoco中,使用的是 \(LDL^T\)分解。这两者我感觉本身计算量的差别不会太大。然而在genesis的计算中,对于自由度的遍历依然可以实现并行化:
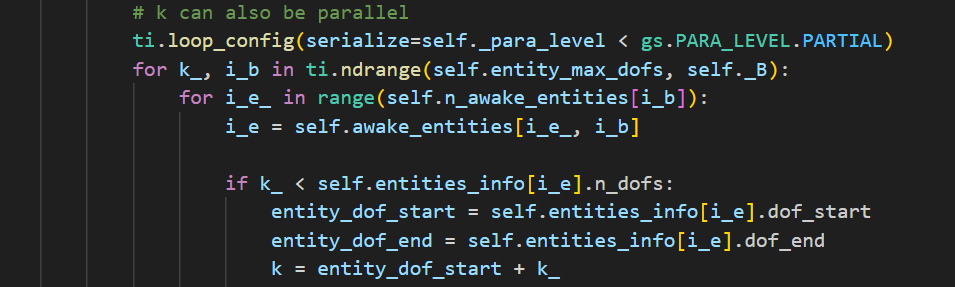
此外,在分解的过程中。mujoco中自己定义了函数,是通过简单的遍历实现的。
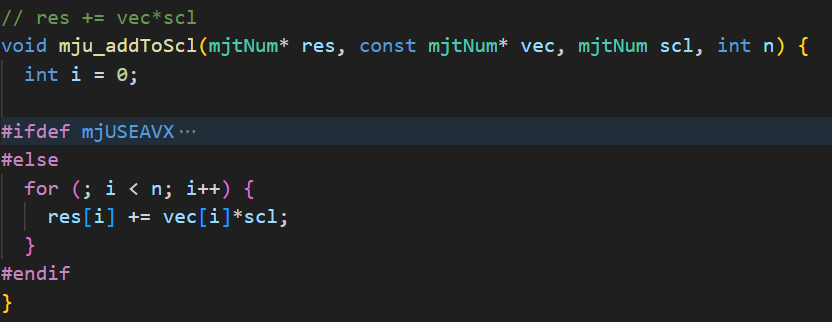
在genesis中,虽然也是遍历,但是它的参数都是通过taichi重构的,可能相较于原生的C语言会有一定的加速。
3. Force Calculation
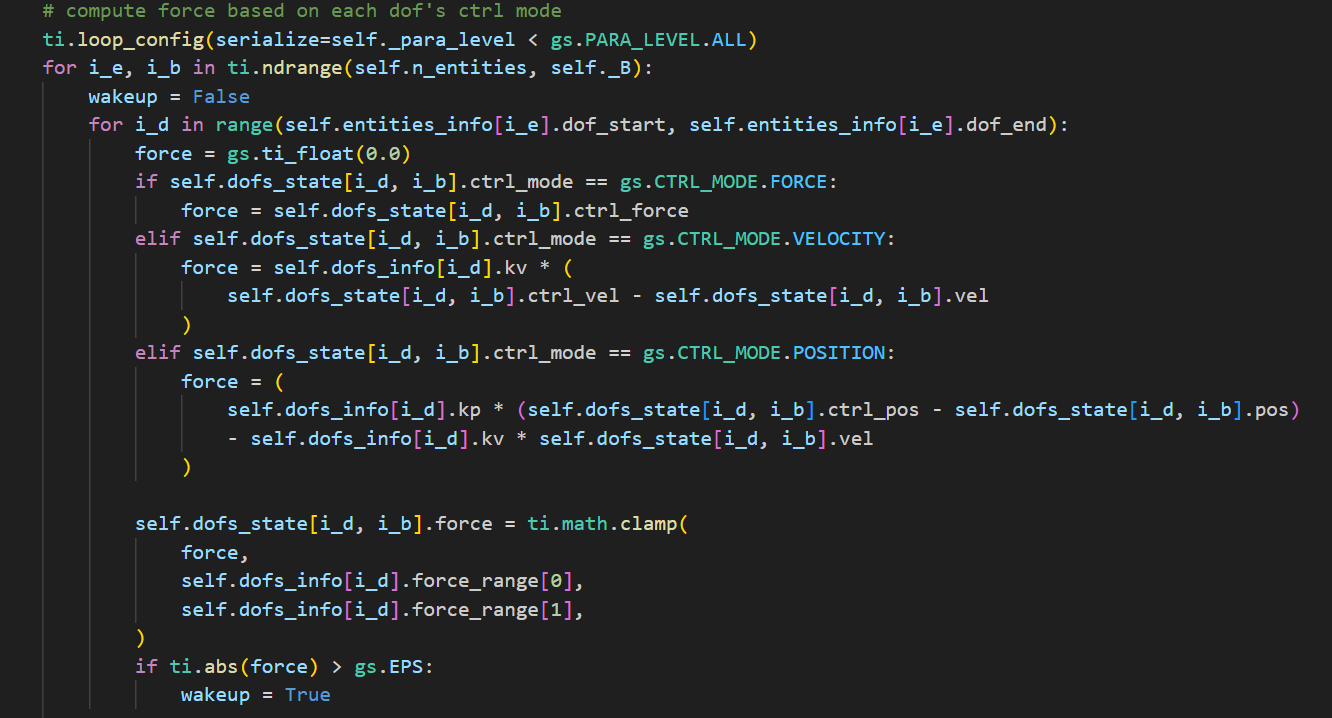
该函数的目的是计算每个自由度上的总力,包括控制力、阻尼力和弹性力。
在力的计算中,genesis中有三种控制模式,根据代码,分别是FORCE、VELOCITY、POSITION。
控制模式:
FORCE模式:- 直接将控制力
ctrl_force应用于自由度。
- 直接将控制力
VELOCITY模式:根据当前速度
vel和目标速度ctrl_vel计算阻尼力:1
force = kv * (ctrl_vel - vel)
kv是速度控制的增益系数。
POSITION模式:根据当前位置
pos和目标位置ctrl_pos计算弹性力和阻尼力:1
force = kp * (ctrl_pos - pos) - kv * vel
kp是位置控制的增益系数。
如果计算出的力大于阈值EPS,则唤醒实体。
此外,force还需要根据如下方式减去弹性力和阻尼力:
1 | force -= qpos * stiffness |
mujoco中也是三种控制,position、velocity和acceleration,大体上是一致的:
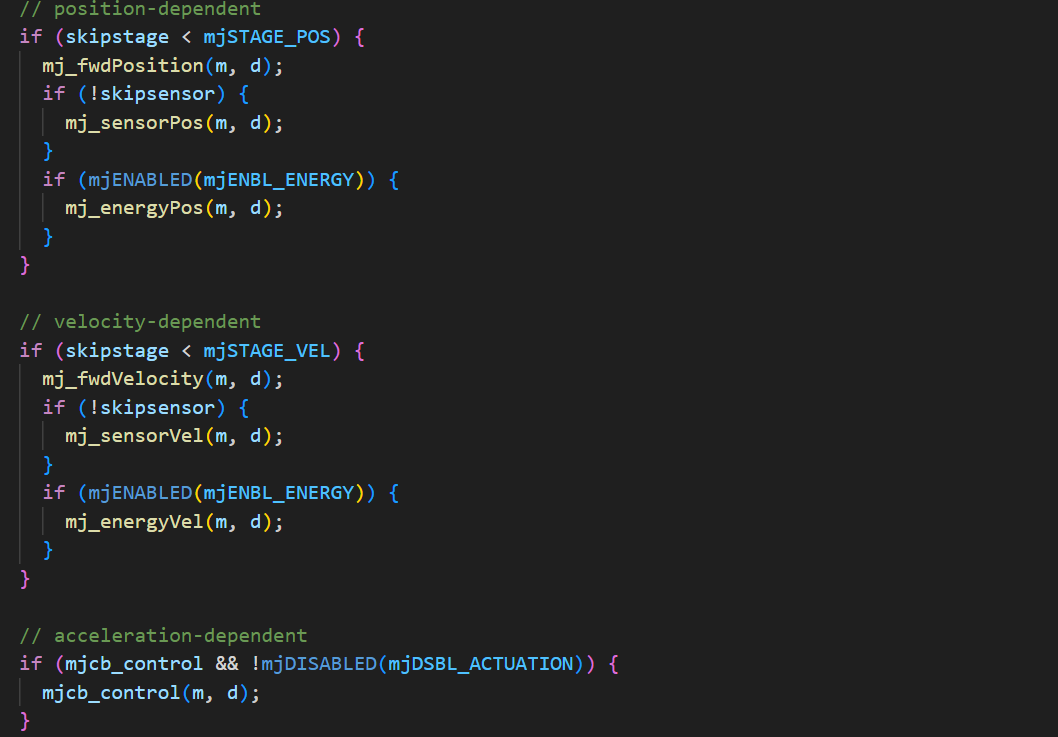
4. Update Acceleration and Force
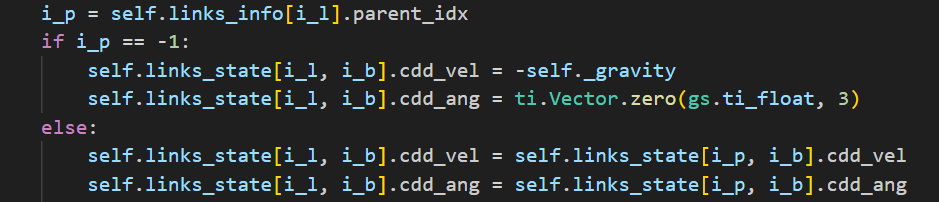
遍历每个Entity的每个Link,是根节点的话,设置线加速度为重力加速度,角加速度为0。不是根节点则继承父节点的加速度。
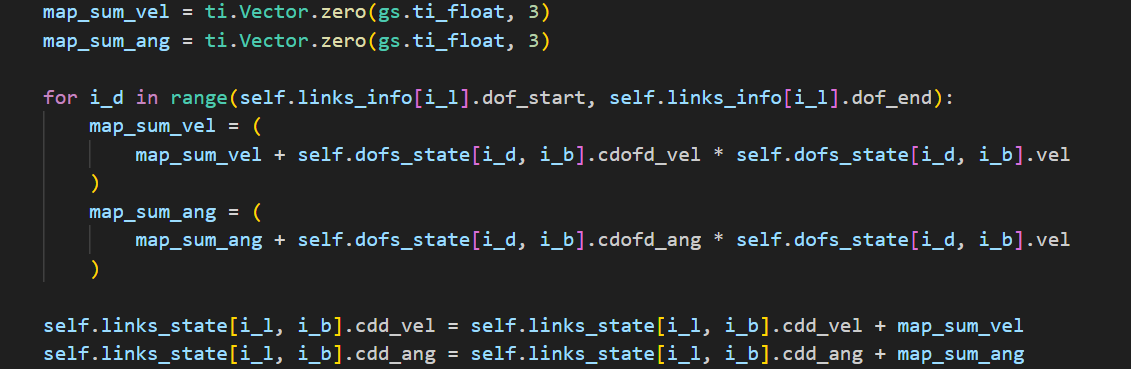
流程:
- 遍历链接的所有自由度(从
dof_start到dof_end)。 - 对每个自由度:
- 根据自由度的速度
vel,计算其对线加速度的贡献cdofd_vel * vel。 - 计算其对角加速度的贡献
cdofd_ang * vel。
- 根据自由度的速度
力和力矩的计算与加速度计算类似。且其中调用的都是@ti.func修饰的矩阵运算函数。
5. Inverse Link Force
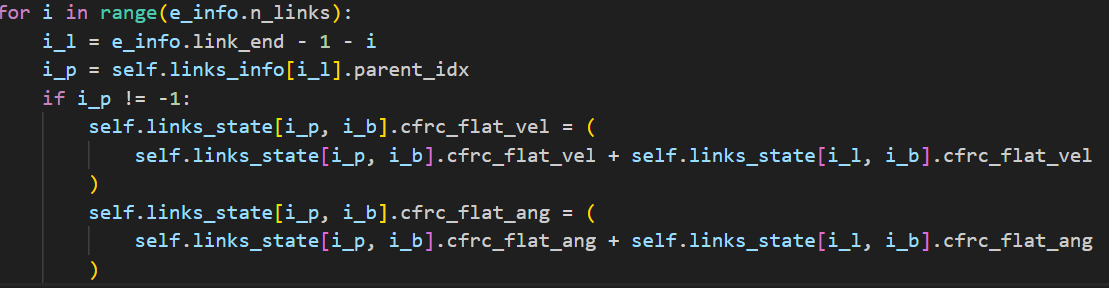
从每个实体的末端链接开始,向父链接累积力。
6. Bias Force

基于链接的累积力和每个自由度的运动相关量,计算偏置力。
分量解释:
cdof_ang和cdof_vel是每个自由度的运动分量(角速度分量和线速度分量)。cfrc_flat_ang和cfrc_flat_vel是链接的累积角力和线力。- 偏置力的计算:通过上述点积操作,将累积的力和自由度的运动相关联,得出自由度上的偏置力。
7. Compute DOF Acceleration
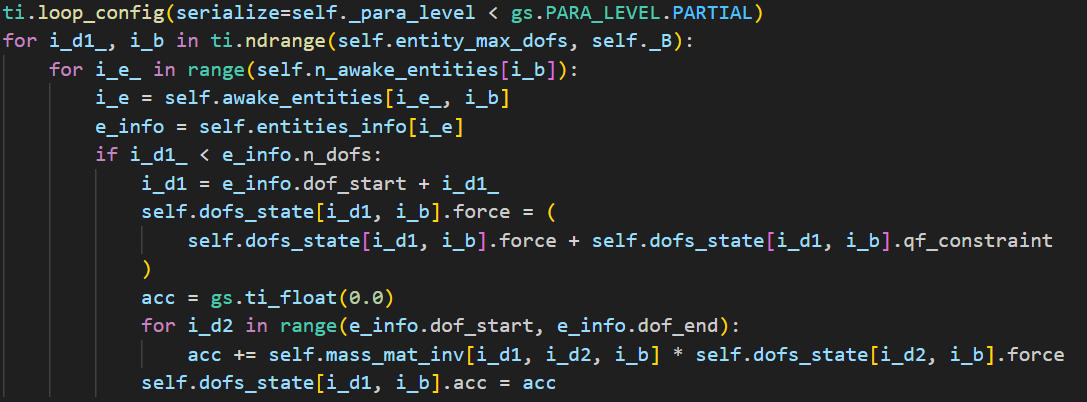
对每个DOF,他要遍历添加所有其他DOF给它施加的约束力。
- 将约束力
qf_constraint添加到当前自由度的总力上。 - 再使用质量矩阵的逆\(M^{-1}\)和总力
force计算加速度acc。
8. Integrate
基于当前自由度的加速度和速度,计算并更新自由度的状态(包括位置和速度)。
基于加速度更新速度\(v\leftarrow v+a\cdot\Delta t\):

更新位置:
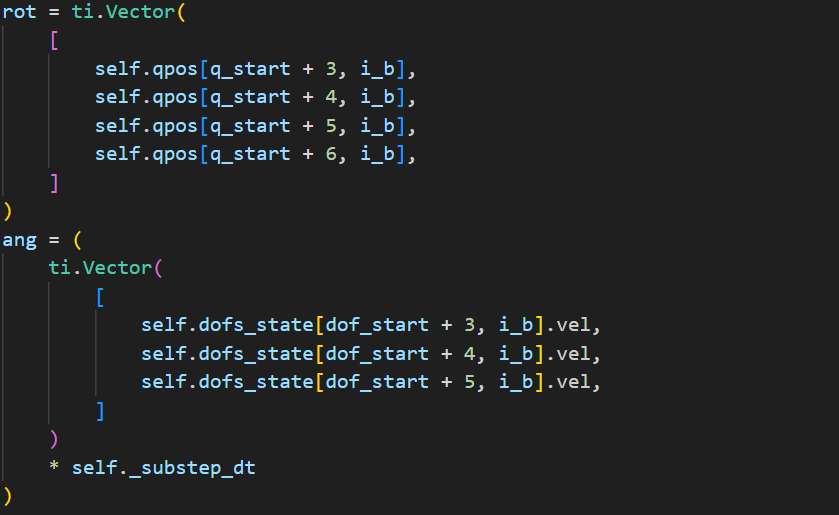
旋转状态和旋转增量:

rot代表刚体在全局坐标系中的当前旋转状态。ang则是时间步内的旋转变化,由角速度直接导出。旋转合并:
将旋转向量\(\mathbf{ang}\)转换为四元数。
再通过四元数乘法更新当前的旋转状态
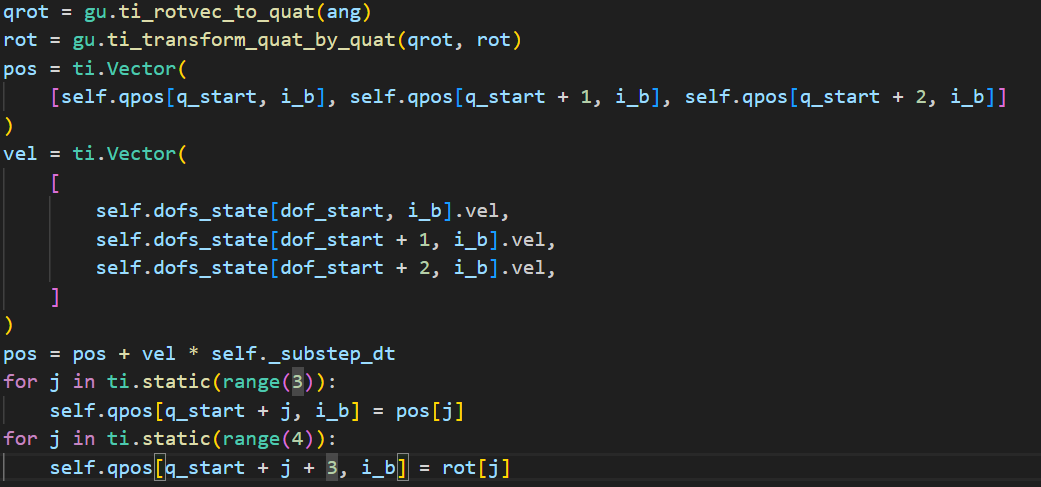
rot。以上是FREE JOINT的更新方式,非FREE的直接根据
vel更新即可:

9. Contraint Force
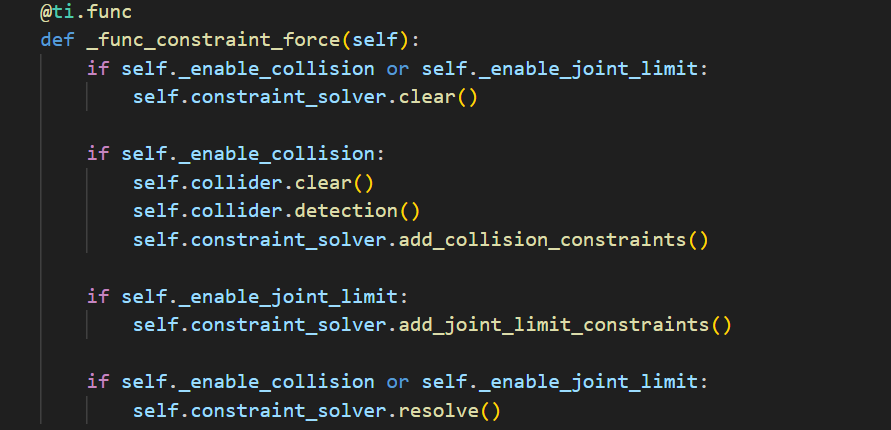
以下详细对比下genesis和mujoco在碰撞检测中的实现:
Broad Phase:
在genesis和mujoco中,都使用了AABB对碰撞检测对进行一个快速的排除。但是它的具体的实现细节又有所不同。
在genesis中,使用的是
Sweep and Prune (SAP)方式,它将所有物体AABB盒的Min点与Max点分别在XYZ轴上投影,如果在某一轴上不满足Max1 > Min2 && Max2 > Min1则不会发生碰撞。在mujoco中,使用的是
Bounding Volume Hierarchical Tree(BVH)算法。它是通过二叉树来管理所有的AABB盒。在计算碰撞时,遍历二叉树以获取所有可能的碰撞对。Narrow Phase:
窄相检测的目的是根据宽相检测检测出的碰撞对再进行细致的计算,获取碰撞接触点、法向量、穿透深度等信息。
窄相检测中,genesis使用的是
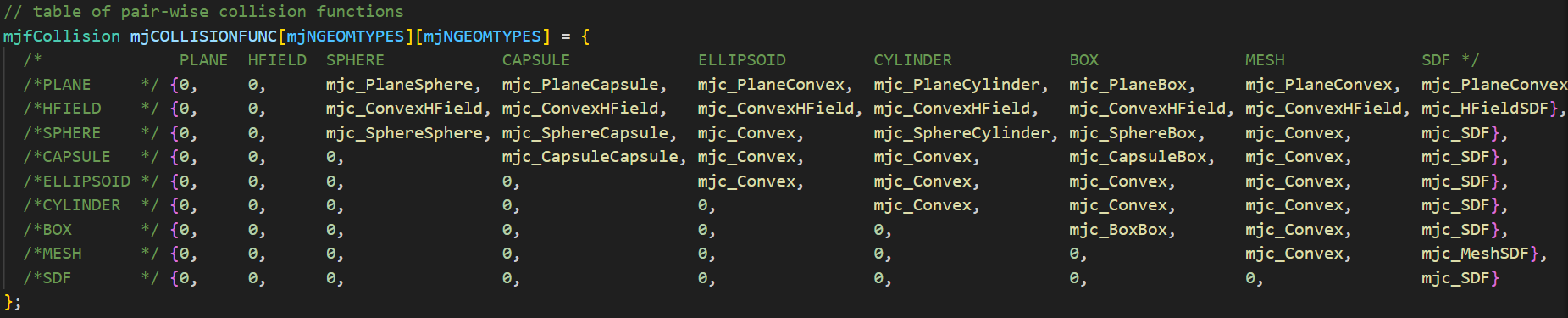
SDF方法。根据物体的类别,SPHERE、TERRAIN、CONVEX或者其他,调用不同的函数。在SDF底层实现中,genesis使用的依然是遍历查询每个顶点,判断是否侵入另一个物体。在mujoco中,定义了一个碰撞函数检测表:
不同于genesis全部计算
SDF,mujoco中对于凸包与凸包间的碰撞,使用了GJK算法来判断凸包是否相交,如果检测到相交,再用EPA算法计算穿透深度和接触点。Add Constraint:
在获取到碰撞信息后,genesis会通过
add_collision_constraints函数将约束施加回去。mujoco中通过函数mj_makeConstraint添加约束。
Performance Analysis
1. Taichi
(1). data structure
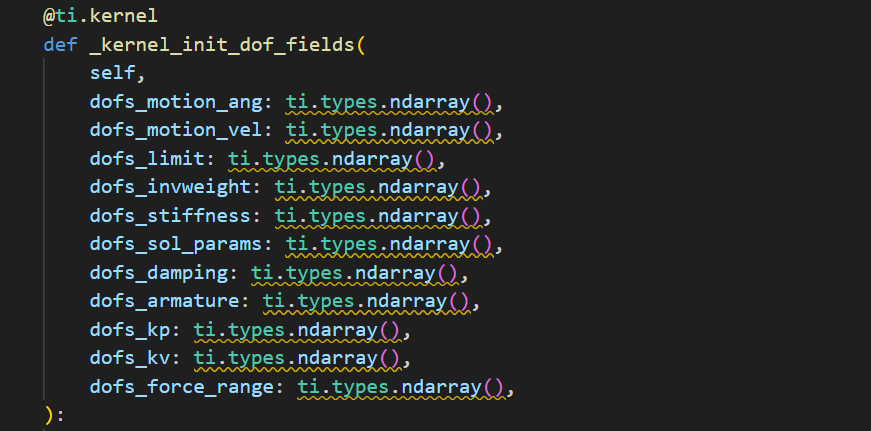
在genesis的初始化中,很多变量就以taichi的数据格式进行初始化了,便于后续高效处理。
(2). Parallelize
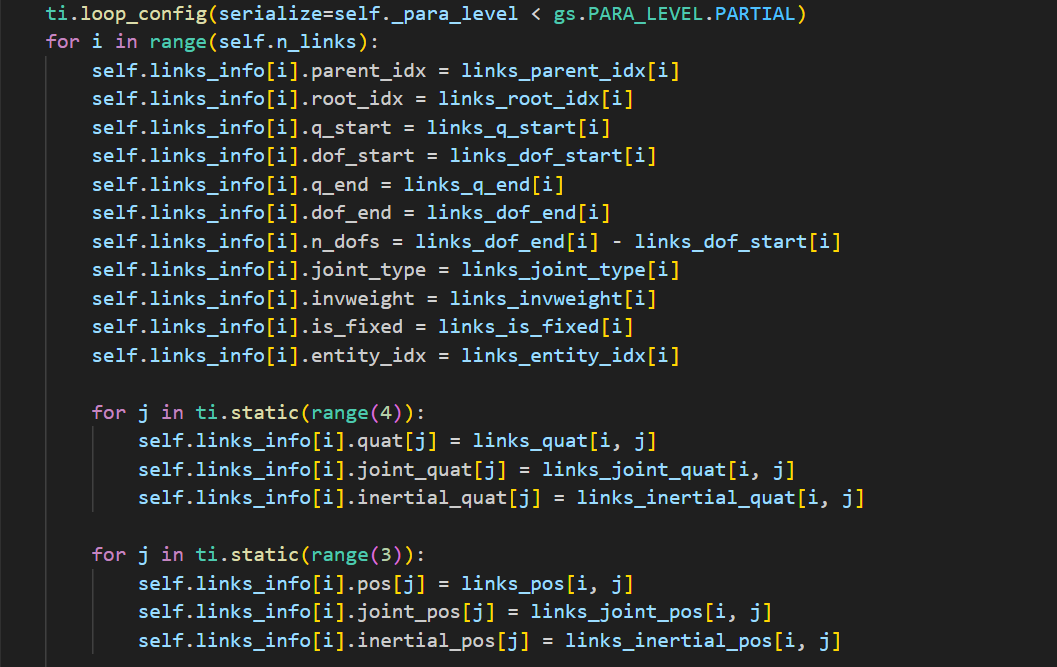
genesis使用了taichi的loop_config函数进行并行化的控制。其中serialize控制是否并行,如果将serialize设置为 True ,则for循环将串行运行。关于_para_level的定义在此:
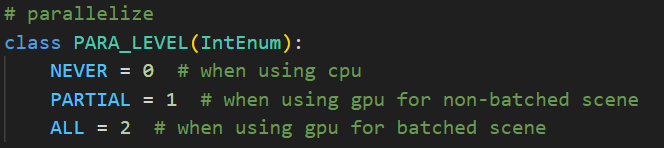
在使用CPU时不进行并行。GPU时根据场景是否分批次进行部分或全部的并行。
2. hibernation
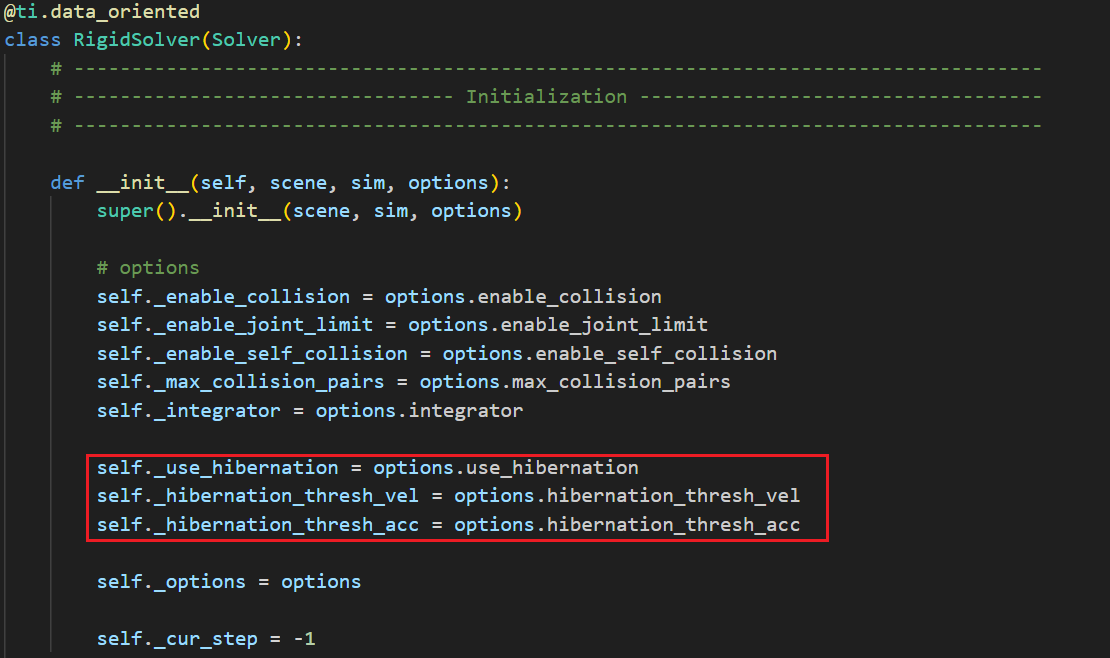
功能启用:
hibernation的启用由self._use_hibernation参数控制。- 当启用时,程序会在初始化中设定相关状态变量,例如
self.dofs_state.hibernated和self.links_state.hibernated标记rigid_solverrigid_solver。
状态检测:
- 判断刚体是否进入 hibernation 的依据是速度和加速度的阈值(
self._hibernation_thresh_vel和self._hibernation_thresh_acc)。如果某个刚体的运动状态低于这些阈值,则会被标记为“休眠”状态rigid_solverrigid_solver。
休眠机制的作用:
- 对于被标记为 hibernated 的刚体,程序会从后续的物理计算中剔除它们。这包括质量矩阵计算、动态求解以及碰撞检测等部分rigid_solver。
- 只有当这些刚体再次被外力或约束影响而超出阈值时,它们才会被重新唤醒并重新加入计算rigid_solver。
核心实现:
self._func_hibernate()函数处理刚体是否应该进入 hibernation 的逻辑rigid_solver。self._func_aggregate_awake_entities()则用于更新非休眠状态的实体列表,以确保只对活跃的刚体执行仿真rigid_solver。
性能优化:
- 通过减少对静态或低动态实体的重复计算,hibernation 可以显著降低复杂场景中的计算开销。
- 适用于场景中存在大量静止或近似静止的物体的情况。
- 标题: Genesis分析
- 作者: Felix Christian
- 创建于 : 2025-01-11 18:57:05
- 更新于 : 2025-02-06 20:13:37
- 链接: https://felixchristian.top/2025/01/11/15-GenesisAnalysis/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。