
主流三维重建方法对比
MeshAnything
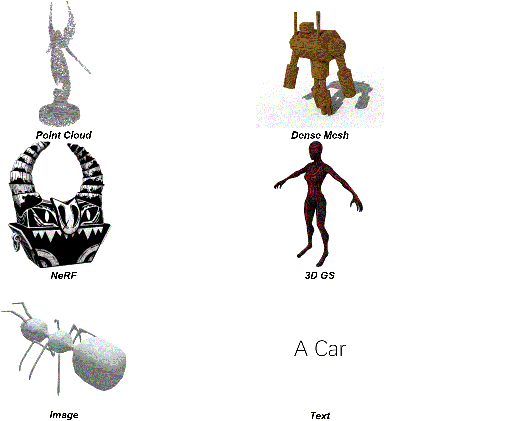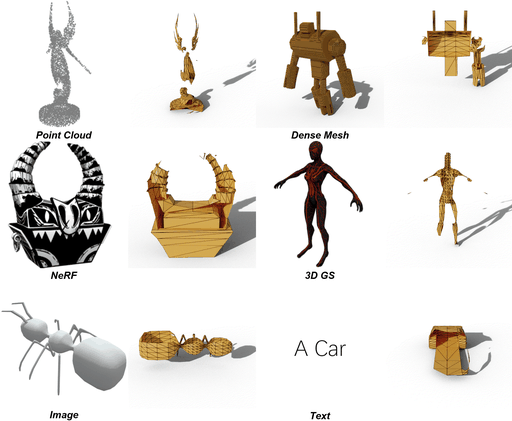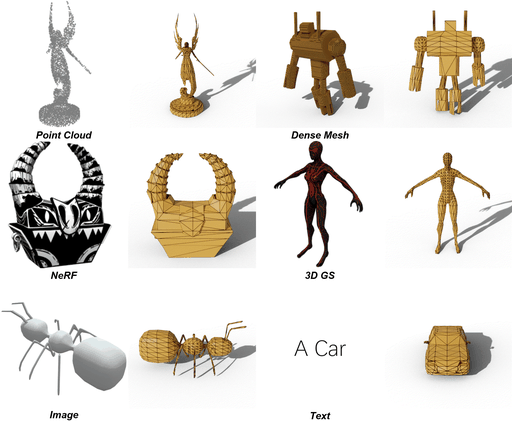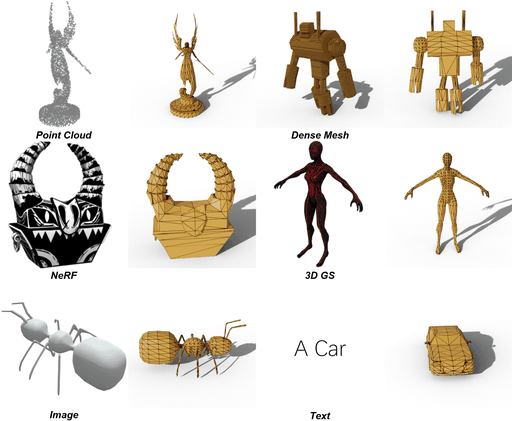
问题背景
当前网格提取方法生成的网格明显不如艺术家创建的网格 (AM, Artist-Created Meshes),即由人类艺术家创建的网格。具体来说,当前的网格提取方法依赖于密集的面并忽略几何特征,导致效率低下、后处理复杂且表示质量较低等问题。为了解决这些问题,论文引入了 MeshAnything ,该模型将网格提取视为生成问题,生成与指定形状对齐的 AM。

上图是对真实形状使用Marching Cubes和MeshAnything,然后对不同voxel size的Marching Cubes进行remesh的结果。现有方法以重构方式提取网格,忽略了对象的几何特征并产生拓扑较差的密集网格。这些方法从根本上无法捕捉锐利的边缘和平坦的表面,如放大图所示。
核心方法
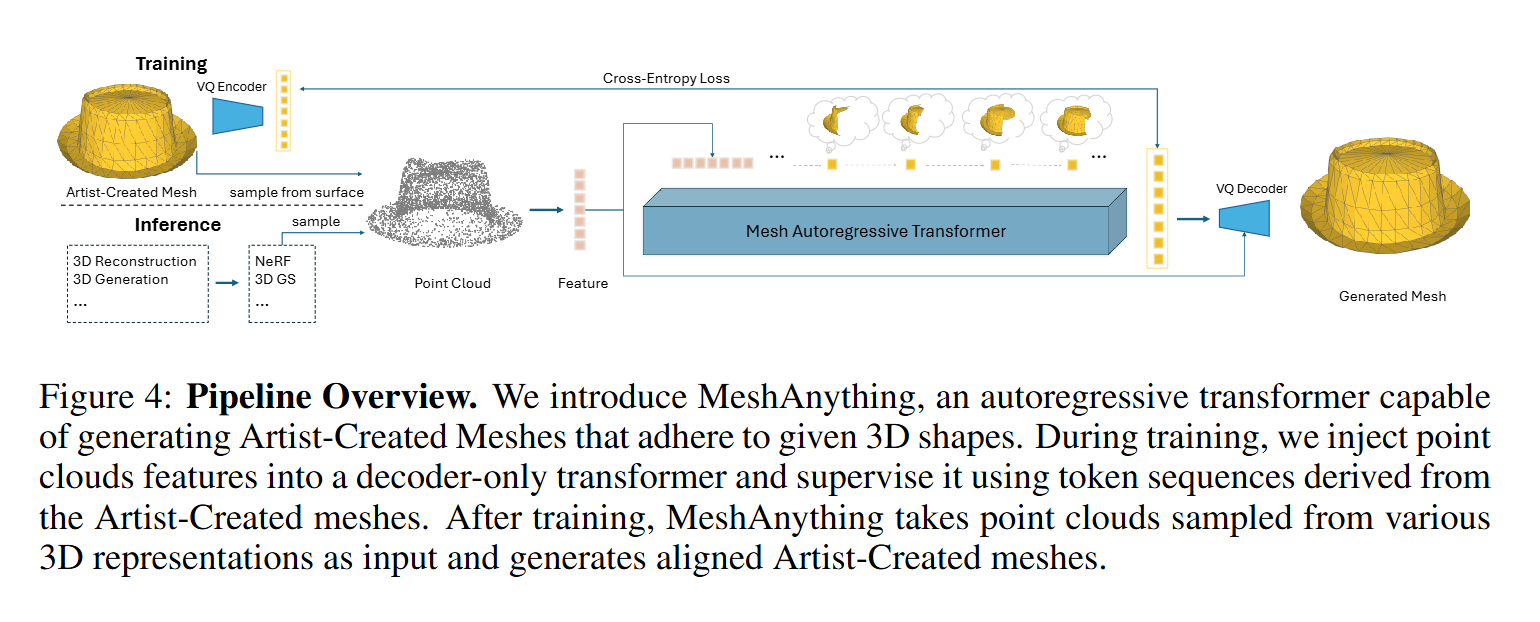
重新定义问题:
- 将网格提取看作一个生成任务,而非重建任务。
- 目标是生成与给定形状对齐的高效拓扑网格(AMs),使其更接近人工设计。
模型架构:
- 使用 VQ-VAE 学习网格的“词汇”(网格编码)。
- 基于“词汇”训练一个仅解码自回归Transformer,以形状条件为输入,生成网格。
- 增强了 VQ-VAE解码器,使其抗噪,能够处理低质量的令牌序列,并利用形状信息辅助解码。
形状条件的设计:
- 选择点云作为输入形状条件,因其具有连续表示性且易于编码。
- 在训练时通过对真实网格进行降质(如使用Marching Cubes生成粗网格)来缩小训练与推理的域差距。
优化训练:
- 在VQ-VAE训练完成后,额外细调解码器,模拟推理中可能生成的低质量令牌序列,并提高对噪声的鲁棒性。
实验结果
- 生成效率: MeshAnything 生成的网格面数比传统方法减少数百倍,同时保留较高的形状对齐质量。
- 拓扑质量: 在用户研究中,MeshAnything的形状和拓扑质量显著优于现有方法,表明其生成的网格更接近艺术家手工制作的标准。
- 泛化能力: 能处理来自各种3D表示(如点云、体素、NeRF等)的输入,支持广泛的3D资产生产管线。
存在问题
第一眼见这个工作的时候,有被震撼到。以为这个工作将多种三维重建方式整合起来了。从它的演示中,看见它可以从三维高斯、图像、文本直接生成几何形状完整但面数较精简的网格。然而自己部署运行之后发现好像并不是这样。
在查阅代码仓库的readme时,发现所给的示例代码全是从点云或者网格进行转化的代码。正疑惑如何将其他表达方式进行转化,于是看了下issues:
关于3D Gaussian转为mesh:
About 3D Gaussians · Issue #29 · buaacyw/MeshAnything
We suggest converting the 3D Gaussians into a mesh before inputting them into our method.
作者直接建议将3D Gaussian转为mesh再作为该方法的输入。(迷惑)
How to convert 3D gaussian splatting to mesh? · Issue #6 · buaacyw/MeshAnything
Hi, I use SUGAR to get high quality mesh from GS and then sample point cloud on the 3D GS. Other methods like 2DGS should also work well. I suggest you run these methods directly in their repos and use the results as inputs for our method.
另一个
issue里,作者提到了两个方法来进行这种转化:SuGaR和2DGS。关于大规模点云转mesh:
large scale pointCloud · Issue #9 · buaacyw/MeshAnything
MeshAnything目前限制在800个face,对复杂mesh或大规模点云可能无法比较好地转化。
关于image和text转mesh:
How to do text and images? · Issue #4 · buaacyw/MeshAnything
The image/text to mesh is achieved by combining with 3D generation methods. We first obtain dense meshes from 3D generation methods and use them as input to our methods. Note that the shape quality of dense meshes should be high enough. Thus, feed-forward 3D generation methods may often produce bad results due to insufficient shape quality. We suggest using results from SDS-based pipelines (like DreamCraft3D) as the input of MeshAnything as they produce better shape quality.
意思就是,通过其他方法生成
dense mesh,然后再作为该方法的输入呗?
大概总结一下就是,这个方法只是将已有的Mesh转化为Artist-Created Meshes而已,包括之前提到的3DGS、image、text转mesh,根本就是通过别的方法实现的。它是将精度高的密mesh在保留大部分几何特征的情况下进行的“简化”和“优化”,让面片数更精简且拓扑结构更符合人类直觉。
(吐槽一句,我感觉这个标题还有最开始的演示,有种标题党的意味。还以为真的是mesh anything)
SuGaR

问题背景
3D Gaussian Splatting 是一种高效的 3D 场景渲染方法,但其优化后生成的大量无结构的 3D Gaussians 不便于生成可编辑的网格(Mesh)。
当前使用 Neural SDF 提取网格的方法计算量大,需多GPU训练,且耗时较长(通常需24小时以上)。
核心方法
表面对齐正则化:
- 引入一个正则化项,强制优化后的 3D Gaussians 分布于场景表面,从而更好地捕获场景几何信息。
- 通过优化 Signed Distance Function (SDF),使 Gaussians 平坦化,并沿着表面分布。
高效网格提取:
- 基于优化后的 Gaussians,采样水平集上的点,使用 Poisson 重建算法生成三角形网格。相比于 Marching Cubes 算法,该方法对稀疏数据更鲁棒,且计算更高效。
绑定 Gaussians 到网格:
- 将优化后的 Gaussians 与生成的网格表面绑定,进一步优化 Gaussians 和网格,通过 Gaussian Splatting 渲染,提升渲染质量。
- 这种绑定使得可以通过编辑网格来实现对场景的修改。
实验结果
- 速度:SuGaR 方法在单 GPU 上仅需几分钟即可提取出高质量网格,远快于基于 SDF 的方法。
- 质量:在多个数据集上的定量评估显示,SuGaR 的渲染质量(PSNR、SSIM、LPIPS)优于其他基于网格的方法,并与仅关注渲染质量的顶尖方法接近。
- 可编辑性:生成的网格与绑定的 Gaussians 可以直接用于动画、重光照、雕刻等操作,提供了更高的灵活性。
踩坑记录
environment.yml 创建环境 fail:创建空环境一步一步安装依赖。
pytorch找不到包:使用国内镜像(需要注意是使用
-f而不是--index-url):1
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 -f https://mirrors.aliyun.com/pytorch-wheels/cu118
pytorch3d找不到包:去Anaconda官网找到对应版本的安装包复制链接再install:
1
conda install https://anaconda.org/pytorch3d/pytorch3d/0.7.4/download/linux-64/pytorch3d-0.7.4-py39_cu118_pyt201.tar.bz2
其他 conda 包找不到:直接pip insatll。(换了国内源都没解决掉,只能出此下策)
CUDA-capable device(s) is/are busy or unavailable:不会解决了,换回AutoDL了。在AutoDL配环境没遇到这么多问题。
卡在 'computing mesh...' : 在 issue 看到了一模一样的情况,目前还没解决这个问题。
2DGS
问题背景
在计算机图形学和视觉领域,视角一致的几何重建与真实感的新视角合成(NVS)一直是重要的研究目标。近年来,基于 3D Gaussian Splatting (3DGS) 的显式方法因其实时渲染能力而受到关注。然而,3DGS 在以下方面存在显著问题:
- 表面几何不精确:3D高斯的体积表示与物体的薄表面特性冲突,导致表面重建质量较低。
- 多视角不一致性:3DGS 在不同视角下计算交点时,由于投影平面变化,产生深度和法线的不一致性。
为了解决这些问题,本文提出了一种新的显式建模方法——2D Gaussian Splatting (2DGS),以提高几何重建的精度和视角一致性,同时保留快速渲染能力。
核心方法
- 方法概述
- 通过二维高斯平面(即二维椭圆盘)来替代三维高斯球体,将场景建模为一组二维高斯分布的集合。
- 这些二维高斯盘通过显式的光线与平面交点计算,实现几何表面和光照的高效表示。
- 结合梯度优化,从稀疏点云和多视角图像中同时优化外观与几何。
- 关键技术
透视准确的二维高斯渲染:利用光线与二维高斯交点的显式计算,避免传统近似方法带来的透视误差。
正则化损失:
- 深度失真损失:通过约束二维高斯沿光线分布的紧密性,确保几何表面稳定。
- 法线一致性损失:约束二维高斯表面的法线方向与深度图梯度对齐,保证表面平滑性。
高效实现:基于CUDA的自定义内核加速训练和实时渲染。
- 优化流程
- 初始化稀疏点云并结合多视角RGB图像,优化二维高斯参数(位置、缩放、方向)。
- 使用正则化损失减少噪声,增强几何表面和视角一致性。
实验结果
- 实验设置
- 数据集:DTU、Tanks and Temples 和 Mip-NeRF360,涵盖不同场景和分辨率。
- 比较方法:隐式表征方法(如NeRF、NeuS)与显式方法(如3DGS、SuGaR)。
- 主要实验结果
- 几何重建:
- 在DTU数据集上,Chamfer距离优于现有方法,特别是在细节捕捉和噪声消除方面。
- 比隐式方法快100倍的训练速度,比其他显式方法(如SuGaR)快3倍以上。
- 新视角合成:
- 在Mip-NeRF360数据集上,新视角渲染质量接近3DGS,且同时提供了更高的几何精度。
- 消融实验:
- 验证了正则化项的有效性:缺失法线一致性会导致表面方向噪声,缺失深度失真损失会导致表面模糊。
- 定量与定性表现
- 定量结果:在DTU数据集上,2DGS的Chamfer距离和PSNR均达到当前最优,同时显著减少了训练时间和模型存储需求。
- 定性结果:相比3DGS和SuGaR,2DGS在复杂几何和细节捕捉上表现更优,能更好地重建噪声较少的表面。
重建效果

上图是训练30000个iteration后生成的mesh。可以看出2DGS生成的mesh还是比较精确的。
GOF
未完待续...
- 标题: 主流三维重建方法对比
- 作者: Felix Christian
- 创建于 : 2024-11-18 13:27:05
- 更新于 : 2024-12-09 13:37:25
- 链接: https://felixchristian.top/2024/11/18/09-Reconstruction/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。