
NeRF Studio简要教程
准备工作
安装NeRF Studio
官方仓库 写的教程已经很详尽了。
1 | git clone https://github.com/nerfstudio-project/nerfstudio.git |
值得注意的是,open3d库只支持python 3.8-3.11,博主是用python 3.10安装的依赖。后面租了个服务器用python 3.12,结果找不到相应版本的open3d,建议还是按推荐配置来。
安装tiny-cuda-nn
在训练过程中,终端出现了如下的warning:
1 | WARNING: Using a slow implementation for the SHEncoding module. |
提示你可以用tcnn进行加速。根据它的提示输入指令:
1 | pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch |
不出意外的话就要出意外了:
先是查看了下文档,说是要求 g++ < 11 ,于是安装了g++-9:
1 | sudo apt install g++-9 |
然后切换版本:
1 | sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 20 |
如果有多个版本好像还得执行以下指令切换:
1 | sudo update-alternatives --config g++ |
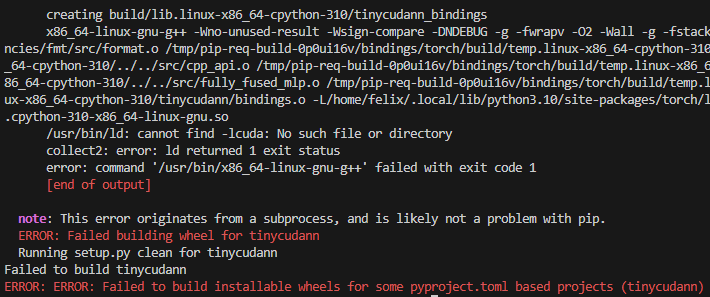
发现还是不行,看报错里有这样一句:
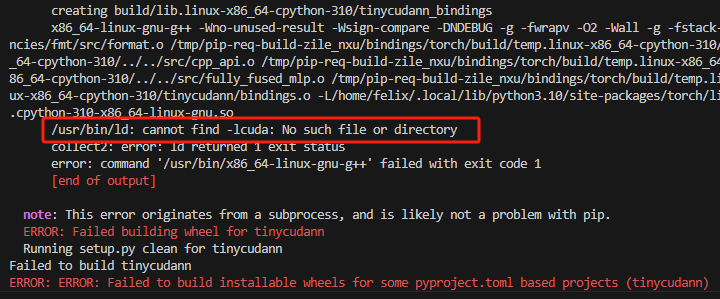
说明问题出在lcuda,g++找不到lcuda。因为博主使用的WSL,cuda库存放在/usr/lib/wsl/lib中,将它复制出来即可:
1 | sudo cp /usr/lib/wsl/lib/* /usr/lib |
然后再次执行安装就成功了。
值得注意的是,在安装tcnn之前,博主用nerfacto训练30000个step用了两小时,而安装之后仅需20分钟,这个提升还是蛮可观的。
报错及解决方案
使用splatfacto训练报错
1. No CUDA toolkit found.
在使用splatfacto进行训练时报错: 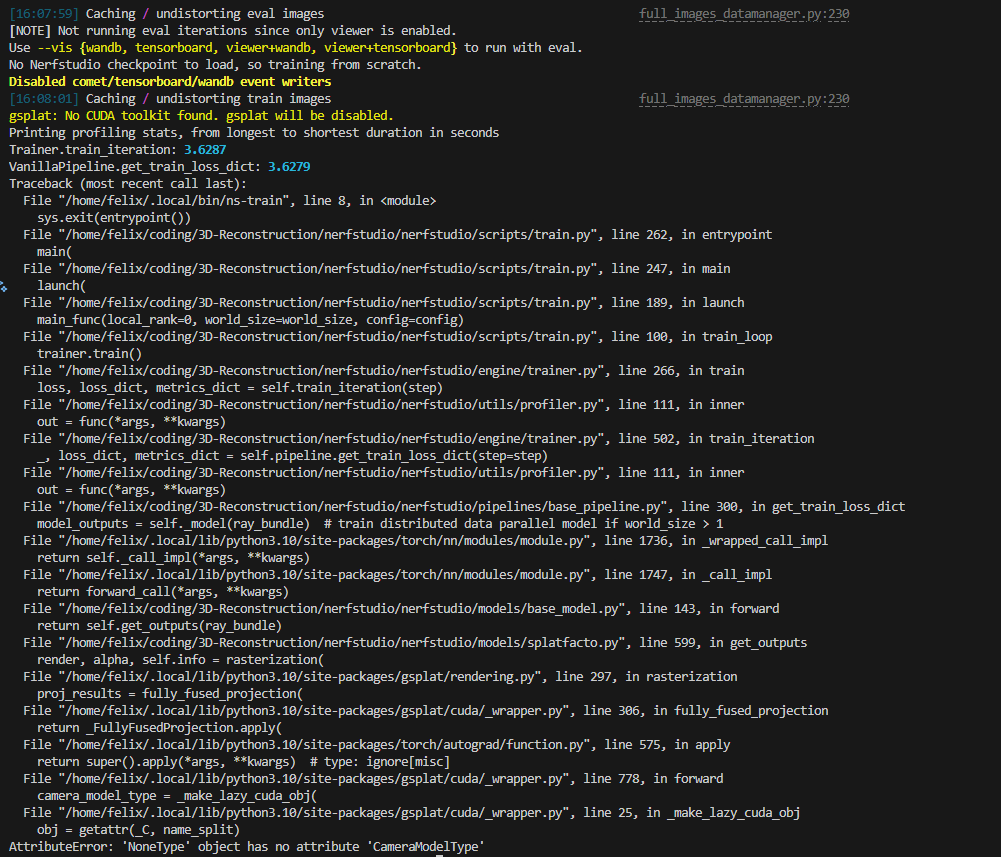
显示CUDA Tookit找不到,然而我的用户目录里是有的。
在github的issue里找到了解决方案:No CUDA toolkit found. gsplat will be disabled. · Issue #249 · nerfstudio-project/gsplat
即,将path添加进去:
1 | export PATH=/usr/local/cuda-12.6/bin${PATH:+:${PATH}} |
可以将这句添加到~/.bashrc里,每次打开terminal就不用再输入一遍了。
2. ninja: build stopped: subcommand failed.
解决上个问题后结果还是报错:
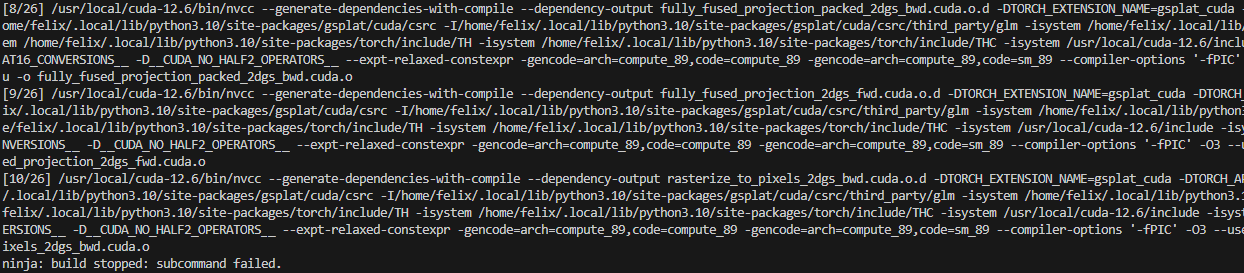
查阅发现是内存不够,进程直接被kill了。自己的WSL虚拟机内存太少了。尝试租服务器,解决。
使用nerfbusters训练报错(未完全解决)
1. ModuleNotFoundError: No module named 'nerfstudio.fields.visibility_field'
在使用nerfbusters方法时,根据文档中的教程安装nerfbuster之后,简单的使用--help也会出现如下的报错:
1 | ModuleNotFoundError: No module named 'nerfstudio.fields.visibility_field' |
切换其他基于NeRF的方法,有的依然会出现这个报错。
然后在issue中找到了相似的情况:
Where's nerfstudio VisibilityFIeld come from? · Issue #17 · ethanweber/nerfbusters
Visibility Field from Nerfbusters by ethanweber · Pull Request #2264 · nerfstudio-project/nerfstudio
其中提到,他们当前使用的branch是nerfbusters-changes,并没有计划把他合并到main branch。
所以需要克隆他们的nerfbusters-changes branch:
1 | git clone -b nerfbusters-changes https://github.com/nerfstudio-project/nerfstudio.git |
然后在根目录执行安装:
1 | pip install -e . |
这样就可以了。
2. `numpy` has no attribute `bool8`. Did you mean: `bool`?
这是因为numpy在1.24更新后将bool8更名为了bool,降级numpy版本即可:
1 | pip install numpy==1.23 |
3. The viewer bridge server subprocess failed.
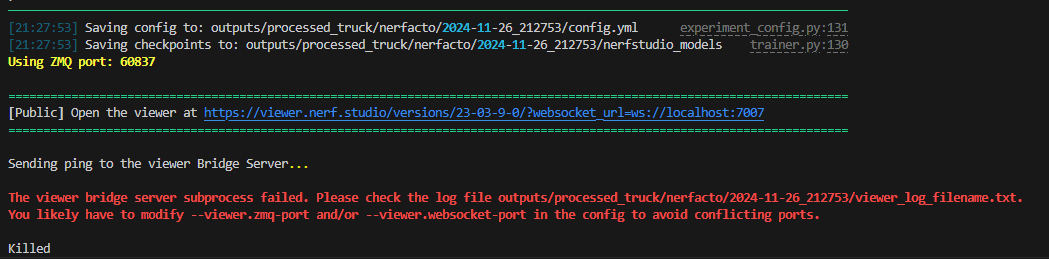
切换分支后运行原有的方法都会出现如下报错。说是viewer的服务启动失败了,通过--viewer.websocket-port更改窗口依然是相同的报错,于是根据提示查看了log:

好嘛,给我原来的module搞没了,我又回原来的分支重新pip install -e .,然后再运行。
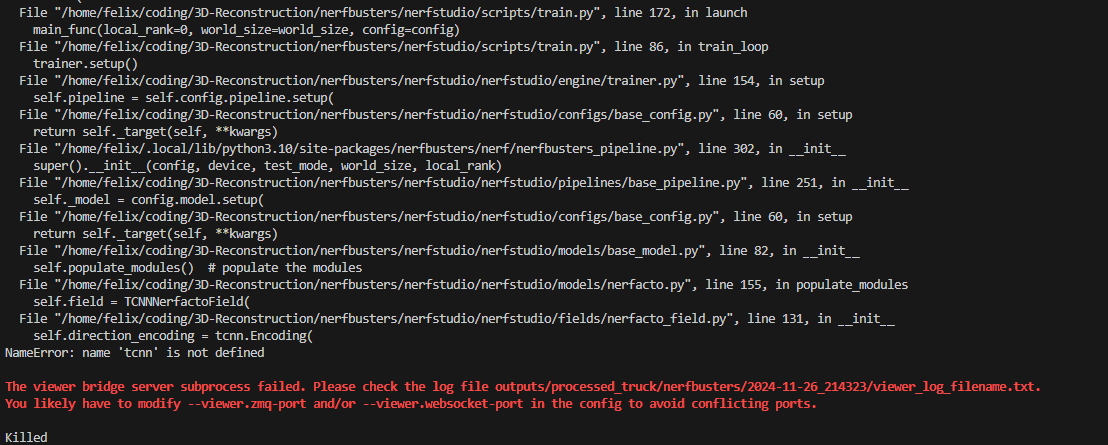
闹鬼了,我不玩了行吧,nerfbusters给劳资滚!😠
使用zipnerf报错
1. ERROR: Failed building wheel for cuda_backend 或者 No module named '_cuda_backend'
在使用
1 | pip install git+https://github.com/SuLvXiangXin/zipnerf-pytorch#subdirectory=extensions/cuda |
安装依赖的时候,出现如下报错:

开始没有管他,直到最后训练的时候又弹出报错:
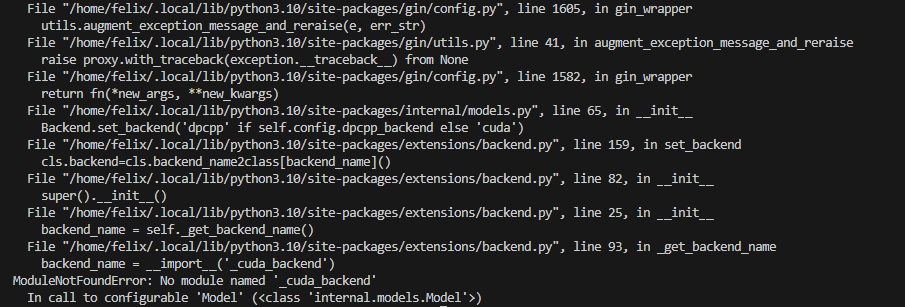
看样子是逃不掉了。
2. AssertionError: pipeline.datamanager.dataparser...

第一次出现这长串报错是因为参数没输对,第二次问gpt说是与 tyro 版本有关,尝试升级 tyro 库以及相关依赖:
1 | pip install --upgrade tyro |
然后看到error怂了:

于是又改回了推荐的版本:
1 | pip install tyro==2.13.3 |
然后再运行就可以了。
3. AssertionError: Colmap path data/processed_truck/sparse/0 does not exist.
这个原因是zipnerf用的数据集格式和nerfstudio好像不完全一致,我用了下tandt的数据集发现可行,但是它会对图像先进行一次下采样。
1 | (nerf2mesh) root@I1dc2923c3f00801cdf:~/3D-Reconstruction/nerf2mesh# python main.py nerfstudio/poster/ --workspace trial_syn_poster/ -O --bound 1 --scale 0.8 --dt_gamma 0 --stage 0 --lambda_tv 1e-8 |
运行结果
nerfacto和splatfacto渲染效果对比
由于背景场景太过杂乱,在导出的时候选择了crop一下,只保留了主体。
对于基于NeRF的方法nerfacto,可以选择导出点云或者网格。导出的网格在meshlab进行可视化,效果如下:

可以看到,poster的内容是比较清晰地还原出来了,然而椅子的形状结构却有些损坏,尤其是越靠近中心缺损越严重。
而对于基于3DGS的方法splatfacto,它只能选择导出gaussian splat。为了对其进行可视化,选择使用了 supersplat 这个工具:
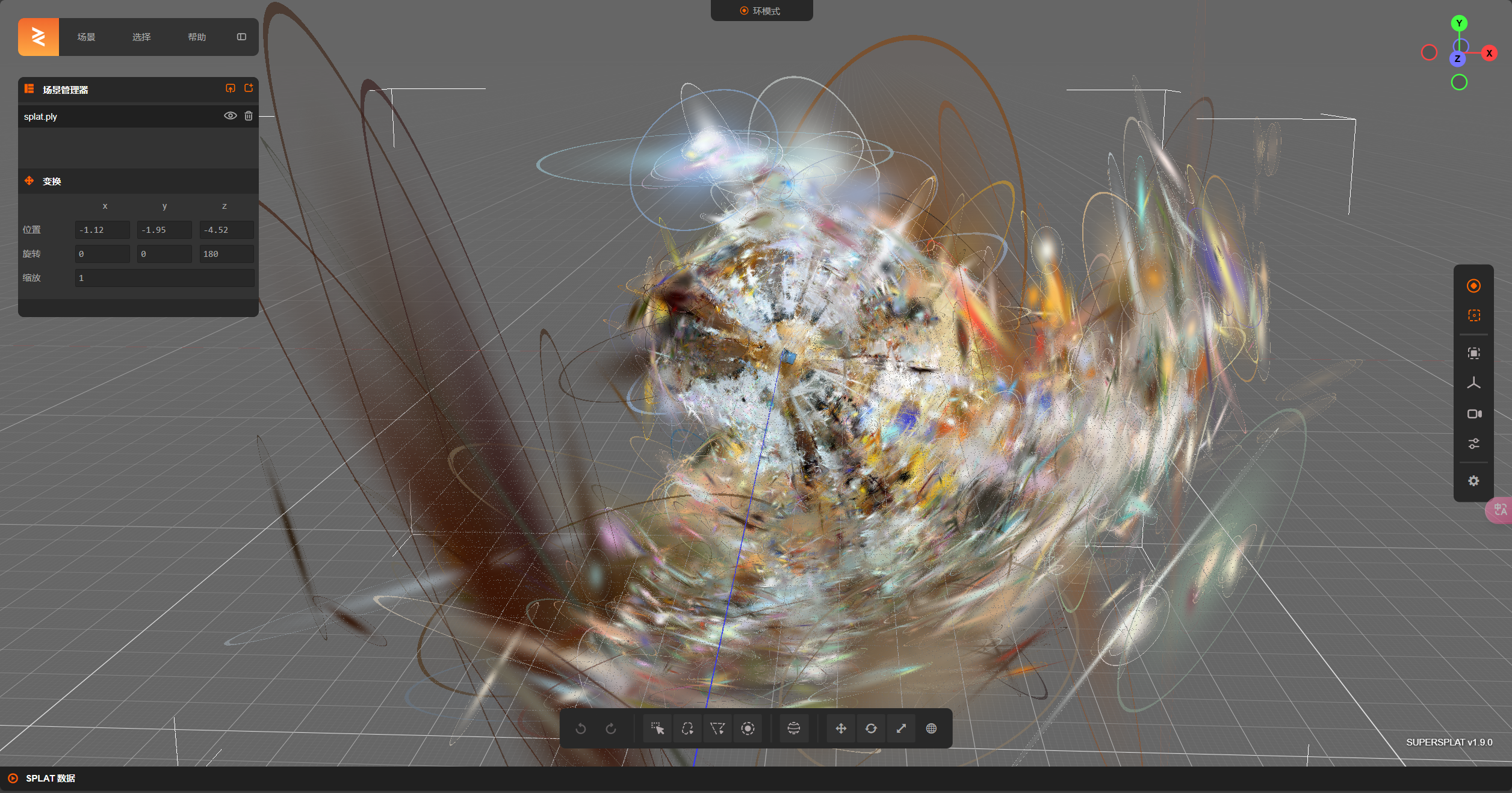
可以看到,除了中心的主体外,为了渲染出背景,在即便是很远的地方也生成了很多个gaussian splat。

将摄像头拉近到主体,发现这个重构效果还是蛮好的。然而如何将gaussian splat转化为网格形式,这是后续工作的重点。
Mesh导出
在NeRF Studio中可以对训练结果进行可视化的导出。支持3D gaussian, point cloud和mesh ,但是对于不同的方法,导出的格式不同。如基于NeRF的方法只能导出点云和网格,而基于3DGS的方法只能导出三维高斯。
训练代码示例:
1 | ns-train nerfacto --data data/processed_truck/ --output-dir outputs/truck_100000 --max-num-iterations 100000 |
可以先对训练结果进行可视化:
1 | ns-viewer --load-config path/to/your/trainresult/config.yml |
然后在网页的export栏可以选择导出参数,并复制导出指令,以possion的导出为例:
1 | ns-export poisson --load-config outputs/truck_100000/processed_truck/nerfacto/2024-11-26_142623/config.yml --output-dir exports/mesh/truck_100000iter_50000face --target-num-faces 50000 --num-pixels-per-side 2048 --num-points 1000000 --remove-outliers True |
还可以选择其他的导出方式,如tsdf:
1 | ns-export tsdf --load-config outputs/truck_100000/processed_truck/nerfacto/2024-11-26_142623/config.yml --output-dir exports/mesh/truck_100000iter_50000face_tsdf --target-num-faces 50000 --num-pixels-per-side 2048 |
或者marching-cubes:
1 | ns-export marching-cubes --load-config outputs/truck_100000/processed_truck/nerfacto/2024-11-26_142623/config.yml --output-dir exports/mesh/truck_100000iter_50000face_tsdf --target-num-faces 50000 --num-pixels-per-side 2048 |
(好像nerfacto的结果不能用marching-cubes)
下面直观展示下导出mesh的效果(前四种是nerfacto,最后一个是用2DGS方法生成的结果):
| possion (30k iters, 50k faces) |  |
|---|---|
| possion (100k iters, 50k faces) |  |
| possion (100k iters, 100k faces) |  |
| tsdf (100k iters, 50k faces) |  |
| 2DGS (2m faces) |  |
可以看到,tsdf提取的网格质量过低,而possion提取的网格相较而言则更精确。总体而言,对于nerfacto方法来说,iteration的提升貌似没有对最终的网格产生比较大的改善,30k的迭代次数已经足够,而face的增加其实也显得不是很必要,50k的面数已经足够表达一个复杂的结构体了。对于2DGS,由于它没有整合到NeRF Studio里,它的重建没有固定面数,最终生成了2m的面,虽然重建效果好很多,但是对计算负载的压力更大。
- 标题: NeRF Studio简要教程
- 作者: Felix Christian
- 创建于 : 2024-11-12 19:27:05
- 更新于 : 2024-12-10 17:28:55
- 链接: https://felixchristian.top/2024/11/12/08-NeRF_Studio/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。