

SplatSim 论文解读
背景
Sim2Real是机器人技术中的一个核心问题,涉及将模拟环境中学到的控制策略转移到现实世界环境中。目前的方法基本都依赖于深度、触觉传感或点云输入等感知方式。相比之下,RGB 图像很少用作机器人学习应用中的主要传感方式。优于 Sim2Real 传输中的其他常用方式。它们捕捉关键的视觉细节,例如颜色、纹理、照明和表面反射率等,这对于理解复杂的环境至关重要。此外,RGB 图像很容易在现实环境中使用相机获取,并且与人类感知紧密结合,使其非常适合解释动态和复杂场景中的复杂细节。
为什么很难将使用 RGB 信息进行模拟训练的策略部署到现实世界呢?是因为机器人在模拟器中观察到的图像分布与它在现实世界中看到的图像分布有很大不同。本文提出了一种新颖的方法来减少 RGB 图像的 Sim2Real 差距。利用 Gaussian Splatting 作为照片级真实感渲染,使用现有模拟器作为物理主干。利用 Gaussian Splatting 作为主要渲染基元,取代现有模拟器中传统的基于网格的表示,以显著提高渲染场景的照片真实感。
方法
- 关键前提:准确分割现实场景中高斯分布表示的每个刚体,并识别其相对于模拟器的相应的齐次变换。那么就可以渲染新姿势下的刚体。
- 底层表示:不使用网格图元,而是使用高斯图作为底层表示。
A. 问题描述
专家
渲染图
B. 坐标系定义和变换
C. 机器人 Splat 模型
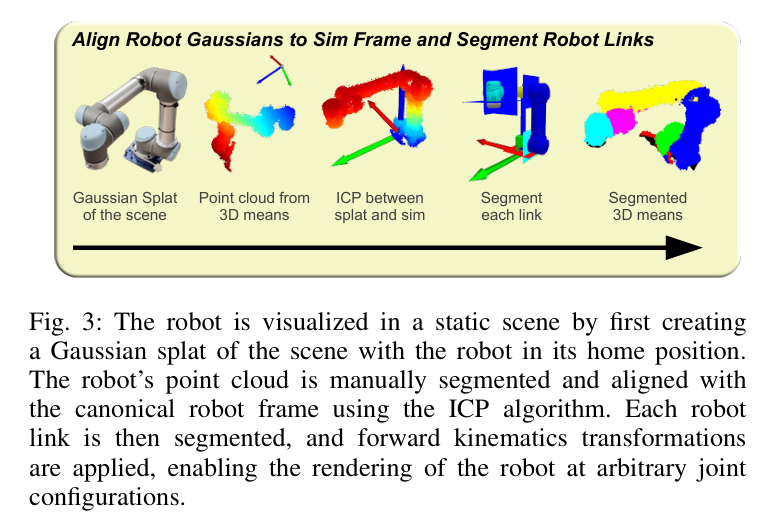
首先创建场景的高斯分布(其中机器人位于其原始位置),在静态场景中对机器人进行可视化。使用 ICP 算法手动分割机器人的点云并与标准机器人框架对齐。然后对每个机器人关节进行分段,并应用正向运动学变换,从而能够以任意关节配置渲染机器人。
D. Object Splat模型
与机器人渲染类似,使用 ICP 来对齐每个对象的 3D 高斯
E. 连接的物体

虽然 CAD 轴对齐的边界框允许对机器人连杆进行直接分割,但某些物体(例如平行钳口夹具)由于与标准轴未对准而带来了挑战,也就是说,仅使用边界框无法将夹具连杆整齐地分割出来。文章使用基于 KNN 的分类器对平行颚式夹具等铰接物体的链接进行分段。
F. 使用 SplatSim 渲染模拟轨迹
既然已经能够在场景中渲染单个刚体,那么可以用它来表示任何模拟轨迹
G. 策略训练和部署
为了在模拟器中从生成的演示
实验
A. 现实世界和模拟中的演示
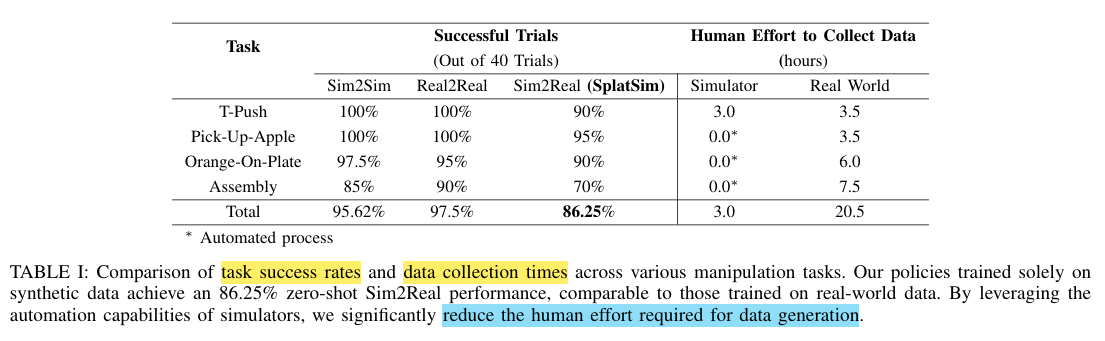
在现实世界中,每项任务的演示都是由人类专家手动收集的。 相比之下,模拟器通过采用基于特权信息的运动规划器简化了这一过程,运动规划器利用特权信息自动生成数据,例如场景中每个刚体的位置和方向。 在有人类专家参与的情况下,模拟器不仅能在演示之间自动重置,从而减少工作量,更重要的是,它利用运动规划器,完全消除了人类干预的需要。这样,只需极少的人工输入,就能生成大规模、高质量的演示数据集。 因此,模拟器大大减少了数据收集所需的时间和精力。 如表 I 所示,在现实世界中收集演示数据需要约 20.5 个小时,而在模拟器中只需 3 个小时就能完成同样的任务,这充分体现了方法的高效性和可扩展性。
B. 零样本策略部署结果
以任务成功率为主要指标,评估了策略在四个接触丰富的真实世界任务中的部署情况。 如表 I 所示,方法实现了 86.25% 的 Sim2Real 传输平均成功率,而直接在真实世界数据上训练的策略成功率为 97.5%,这凸显了方法的有效性。 所有实验均使用配备了 Robotiq 2F-85 抓手和 2 个英特尔 Realsense D455 摄像头的 UR5 机器人,并在英伟达 RTX 3080Ti GPU 上部署了扩散策略。
- T-Push 任务: T-Push 任务由 Diffusion Policy推广,可捕捉非触觉操作的动态,其中涉及控制物体移动和接触力。 在训练中,人类专家使用 Gello teleoper-ation,在模拟中收集了 160 次演示。 测试时,机器人从随机位置出发,在零样本 Sim2Real 传输中取得了 90% 的成功率(36/40 次试验),如表 I 所示。 这一结果表明,框架在真实世界的演示中无需微调就能有效处理推动的动态过程。 此外,方法与 Real2Real(40/40)和 Sim2Sim(40/40)的性能相当。
- Pick-Up-Apple 任务: Pick-Up-Apple 任务涉及在三维空间中抓取和操纵物体的完整姿态(即位置和方向)。 该任务旨在评估机器人在使用论文的模拟渲染场景进行训练时的抓取能力。 运动规划器利用模拟器中的特权状态信息(场景中每个刚体的准确位置和方向),生成了 400 个具有随机末端执行器位置和方向的演示。 如表 I 所示,在真实世界的试验中,策略在零样本 Sim2Real 传输中取得了 95% 的成功率(38/40 次试验)。
- Orange on Plate 任务: 在这项任务中,机器人必须捡起一个橘子并将其放在盘子里。 在模拟过程中,运动规划器获取了特权信息,并生成了 400 次演示。 在训练过程中,末端执行器的位置和初始抓手状态是随机的。 测试期间,机器人总是从原点开始。 论文在 Sim2Real 的零点转移中取得了 90% 的成功率(36/40 次试验)。
- Assembly 任务: 在这项任务中,机器人必须将一个长方体块放在另一个长方体块的顶部。 机器人从原点开始抓取绿色立方体,并将其放到红色立方体的顶部。 这项任务特别艰巨,因为机器人必须精确放置,否则立方体就会掉落,导致失败。 论文的 Sim2Real 策略在这项任务中的表现为 70%(28/40 次试验),而 Sim2Sim 的表现为 95%,Real2Real 的表现为 90%。
C. 量化机器人渲染
通过与真实世界的图像进行比较,论文定量评估了在不同关节配置下渲染的机器人图像的准确性。 论文评估了 300 个不同机器人关节角度下的机器人渲染质量。 为了衡量渲染图像与真实世界图像之间的相似性,论文采用了图像渲染评估中常用的两个指标: 峰值信噪比(PSNR)和结构相似性指数(SSIM)。 尽管关节配置各不相同,但渲染图像的平均 PSNR 和 SSIM 分别达到了 22.62 和 0.7845,表明模拟图像非常接近真实世界 RGB 观察图像的视觉质量。
D. 数据增强的效果
为了量化数据增强对策略在模拟与真实环境中性能的影响,论文对经过训练的策略进行了有增强和无增强的对比实验。 虽然在一致的环境(如 Sim2Sim 或 Real2Real 场景)中,扩散策略在没有增强的情况下也能有效执行,但将在模拟环境中训练的策略转移到真实世界时,由于渲染无法捕捉动态细节(如不断变化的反射和阴影),因此会引入领域偏移,从而需要额外的鲁棒性。 论文在训练过程中加入了随机噪音添加、色彩抖动和随机擦除等增强功能,以应对这些变化。 在 B 节的四项任务中,这些增强措施将该策略的性能从 21% 提高到 86.25%。
结论
在这项工作中,论文利用高斯泼溅技术(Gaussian Splatting)作为一种逼真的渲染技术,并与现有的基于物理交互的模拟器集成,从而缩小了基于 RGB 的操作策略的模拟与真实之间的差距。 论文的框架实现了在模拟中训练好的基于 RGB 的操作策略到真实环境中的零样本转移。 虽然论文的框架推动了当前最先进技术的发展,但它仍局限于刚体操纵,无法处理布、液体或植物等复杂物体。 未来计划将现有的框架与基于强化学习的方法相结合,以获得更多动态技能。还将进一步改进系统,以便在现实世界中训练和部署机器人执行高度复杂和接触丰富的任务。
- 标题: SplatSim 论文解读
- 作者: Felix Christian
- 创建于 : 2024-11-06 15:14:00
- 更新于 : 2024-11-20 20:46:33
- 链接: https://felixchristian.top/2024/11/06/06-SplatSim/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。